RAMBUS DRAM: очередной виток технологии
Введение
На протяжении многолетнего развития технологии динамической памяти двумя определяющими факторами увеличения пропускной способности являлись и являются в настоящее время наращивание ширины шины данных и частоты функционирования, что влечет за собой разработку новых интерфейсных решений. Сначала это были модули SIMM с однобайтной шиной данных, насчитывающие до восьми микросхема памяти. Однако эволюция в этом секторе заменила следующее поколение 32bit SIMM на восьмибайтные модули DIMM.
В 1999 году корпорация Rambus анонсировала новую технологию динамической памяти — Direct Rambus DRAM (DRDRAM), — позволяющей восьмикратно повысить пиковую пропускную способность относительно повсеместно доминирующего в то время PC100 SDRAM при условии равной ширины шины данных этих двух интерфейсов. Тем не менее, первым шагом молодой технологии был всего лишь модуль RIMM с 16bit шиной данных. Как и предыдущие технологии динамической памяти, Rambus DRAM также двигается параллельными путями, постепенно увеличивая пропускную способность расширением внешнего интерфейса, однако при этом не вводя кардинальных изменений в сами устройства динамической памяти (микросхема DRDRAM) и интерфейс коммуникаций с контроллером. Поскольку в основе данной технологии лежит концепция канальной иерархии, интерфейс можно расширять просто объединяя между собой несколько каналов — в результате делается возможным создание 32bit и даже 64bit модулей RIMM.
Однако, как уже было замечено, пропускную способность можно поднимать еще и увеличением частоты функционирования. Если принять во внимание, что в конечном итоге ширина шины данных интерфейса коммуникации микросхем памяти и контроллера остается постоянной, то, отбросив влияние внешних факторов воздействия, следует сконцентрировать свое внимание непосредственно на внутренней архитектуре самих микросхем. Поэтому, несколько позднее, Rambus совместно со своими вендорами приступила к разработке более совершенной внутренней архитектуры DRDRAM — замена «текущей» зависимой организации логических банков ядра на независимые должна помочь в частности уменьшить используемую площадь кристалла при условии одинаковой емкости микросхемы. Изменение внутренней структуры банков также оказывает непосредственное влияние на эффективную задержку ядра и конечную действительную пропускную способность подсистемы, поскольку, как показывают исследования, аддитивная зависимая структура логических банков понижает производительность подсистемы в сравнении с аналогичной многобанковой независимой.
Таким образом, дальнейшей стратегией развития технологии Direct Rambus DRAM было выбрано расширение интерфейса модуля RIMM и изменение внутренней архитектуры микросхемы памяти — об этом и пойдет речь в настоящей статье.
Физический слой DIRECT RAMBUS
Как и любая другая технология, Direct Rambus характеризуется физическим и логическим слоями. Физический слой (Physical Layer) подсистемы определяет электрический интерфейс объединения компонентов системы в канале, включая высоко- и низкоскоростную сигнальную логику, и последовательность проведения инициализации оборудования. Высокоскоростной канал Rambus Channel позволяет добиваться исключительной эффективности комбинацией большого числа технических решений, включающих в себя плотную упаковку компонент, высококачественные передающие сигнальные линии с четко и скрупулезно рассчитанной топологией и трассировкой, применение сигнальной логики с малым размахом активных уровней, передачу информации по фронту/срезу (на уровне логического слоя фронт/срез именуются как нечетный/четный интервалы соответственно — odd/even) синхросигнала, псевдо-дифференциальные приемники и источник дифференциальных синхросигналов, а также устройства управления, осуществляющие контроль выполнения текущих операций, слежение за влиянием внешних факторов и поддерживающие прецизионность тактирования. Используя новейшие технические решения в методах упаковок микросхем и технологии изготовления печатных плат для модулей памяти, технология Rambus предоставляет максимально производительное и надежное решение за сравнительно невысокую цену. Так, например, плотная упаковка весьма важна, поскольку микросхемы используют корпуса CSP поверхностного монтажа, которые имеют малые габаритные размеры, термостойкий материал и очень короткую длину сигнальных выводов, что очень актуально для устройств подобного класса и позволяет уменьшить собственную индуктивность вывода и обеспечить более низкую емкость на входе.
Конфигурация подсистемы памяти DRDRAM строится по двум схемам: полная топология с длинным каналом (Long Channel System) и локальная система с коротким каналом (Short Channel System). Топология с применением длинного канала применяется в качестве базовой подсистемы памяти с возможностью модульного расширения. Короткий канал, в свою очередь, характерен для локальных изолированных систем, где возможность модульного расширения исключена изначально, поэтому особого интереса в данном вопросе не представляет.
{kind=link}
{kind=link}
Типичная
подсистема Direct Rambus с длинным каналом состоит из контроллера (RMC
— Rambus Memory Controller), до трех разъемов (RIMM Connector) под модули
памяти (RIMM — Rambus In-line Memory Module), формирователя синхросигналов
(DRCG — Direct Rambus Clock Generator), источника питания и дискретных
компонентов, осуществляющих терминацию (оконечную согласующую нагрузку).
Каждый разъем может заполняться либо модулем памяти, либо продолжителем
канала (D-RIMM-CONT), однако система должна иметь как минимум один RIMM на
канал. В свою очередь, один модуль памяти может содержать от 1 (реально —
от 4) до 16 микросхем памяти при общей полной нагрузке в 32 устройства на
канал.
{kind=link}
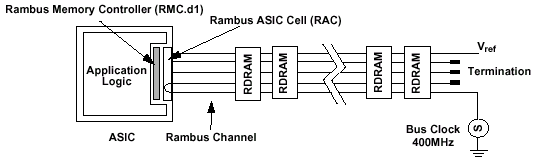
Собственно, сам интерфейс соединения контроллера с микросхемами памяти
называется каналом
или шиной RAMBus и включает в себя 18bit шину данных DQ(A,B)[8:0],
подразделяющуюся на A и B байты, 3bit интерфейс управления строкой
ROW[2:0], 5bit интерфейс управления столбцом COL[4:0], две
дифференциальные синхропары CTM/CTMN и CFM/CFMN, два высокоскоростных
CMOS-сигнала управления SCK и CMD, и низкоскоростной интерфейс
инициализации SIO[1:0]. Таким образом, канал RAMBus является
высококлассной соединительной структурой, ограниченной контроллером памяти
с одной стороны и серией нагрузочных сопротивлений (терминаторов) — с
другой. Кроме чего есть еще пять интерфейсов питания (VRSL,
VCMOS, VTERM, VDD и VDDA), две
разновидности линии «заземления» (GND/GNDa) и вывод подачи опорного
напряжения (VREF — статический высокоомный, низкоамперный
вход).
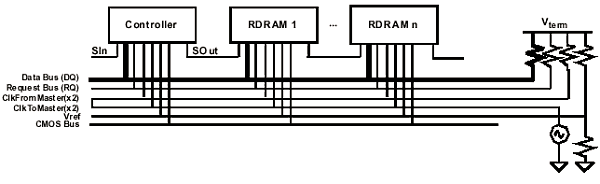
Разъем памяти RIMM-CONN состоит из двух рядов выводов, расположенных с внутренних противоположных сторон, каждый из которых в силу уникальности структуры составляет порт (Port). Левый (Left Port) и правый (Right Port) порты электрически абсолютно идентичны и взаимозаменяемы — соответственно каждый модуль памяти RIMM имеет по два порта. В действительности, направление распространения сигналов по модулям не имеет никакого значения и они могут проходить по портам в разных направлениях: входить через левый порт и выходить через правый, или наоборот. Поэтому условно порты подразделяются на входящий (Input Port) и исходящий (Output Port) в зависимости от направления распространения сигнала. Например, по модулю RIMM сигналы заходят через входящий порт, проходят через все микросхемы в цепи и выходят через исходящий. Исключение в данном случае составляет двунаправленный интерфейс инициализации SIO: каждый разъем имеет два вывода, которые для сигнала SIO всегда являются входным (SIN) и выходным (SOUT).
Передача данных осуществляется только между управляющим устройством и микросхемами памяти, и никогда не происходит непосредственно между микросхемами. Сигнал от микросхемы памяти распространяется в оба направления с половинной амплитудой: поскольку устройство подключено к середине линии, полный сигнал делится пополам. На «зажимах» контроллера, в точке соединения внешних выводов с сигнальными линиями канала, приходящий импульс от микросхемы отражается от ненагруженного конца линии, и, складываясь, удваивается по амплитуде. Суперпозиция приходящего и отраженного сигналов, и согласованное сопротивление со стороны микросхемы памяти обеспечивает поток данных от RDRAM к управляющему устройству с максимальной скоростью и необходимым размахом между активными уровнями. Эффективная (действительная) передача данных осуществляется по фронту/срезу синхросигнала частотой 300/350/400/533 MHz, удваивая результирующую «линейную» пиковую пропускную способность (количество передаваемой информации по одной сигнальной линии за единицу времени) до 600/711/800/1066 Mbps/p — соответственно один бит информации при такой частоте передается за 1.66/1.40/1.25/0.93 ns. При использовании DDR-технологии передачи информации, один такт синхросигнала условно разбивается на 2 тика (tick), по длительности составляющих по половине цикла CFM (полупериод) каждый.
Генератор синхросигналов (DRCG) вырабатывает импульсы с частотой 267-533 MHz, которые распространяются от крайней точки канала (точка соединения выводов формирователя и сигнальных линий канала) к контроллеру, где разворачиваются и по другой линии идут в обратном направлении, после чего попадают на терминаторы и «гасятся». Для синхронизации разнонаправленных потоков используются дифференциальные синхропары: CFM (Clock From Master) для сигналов, идущих к микросхеме памяти от контроллера, и CTM (Clock To Master) — для сигналов, идущих в обратном направлении. Согласование становиться возможным благодаря двум блокам автоподстройки длительности задержки в составе RAC, которые производят синхронизацию исходящих и входящих по отношению к контроллеру сигналов: блок передачи (TDLL — Transmit Delay Locked Loop) и блок приема (RDLL — Receive Delay Locked Loop). Передача команд и данных (блок TDLL) к микросхемам памяти основана на эффекте точной 180° квадратурной фазы, выполняемой в цикле CFM. Все сигналы, распространяющиеся по направлению к управляющему устройству, синхронизируются входящими тактовыми импульсами, а сигналы, исходящие из контроллера — импульсами, идущими по направлению к нагрузке (функции блока RDLL).
Вообще говоря, современная технология Direct Rambus DRAM поддерживает лишь 800/1066 MHz результирующие частоты обмена данными, которые идеально подходят для систем, использующих 100/133 MHz задающий системный синхросигнал. Поэтому в дальнейшем ограничимся рассмотрением именно этих частот.
Direct Rambus позволяет каналу поддерживать так называемый источник мультисинхросигнала (MCD — Multiple Clock Domain), дающий возможность создавать длину сигнальных трасс протяженностью до пяти тактовых периодов (при использовании топологии с длинным каналом), начиная от источника сигнала и заканчивая последним устройством в структуре. В порядке полного согласования между первой и последней микросхемой RDRAM в канале протокол предусматривает программирование задержки чтения (Read Delay) для каждого устройства. Для оптимизации работы контроллер может отслеживать и определять наиэффективнейшую задержку чтения, одну для всех устройств. Необходимо отметить, что записываемые данные могут быть отправлены по следующему фронту синхросигнала за транзакцией чтения — сразу после получения считываемой информации управляющее устройство может выдать данные для записи безо всякой задержки. Тем не менее, транзакция записи, идущая сразу за транзакцией чтения, обычно должна выполнить короткую задержку, эквивалентную длительности периода восстановления канала (промежуток времени, необходимый для получения подтверждения приема устройством команды/данных, и равный длине пробега сигнала от активной микросхемы до контроллера, Round-trip length of the Channel): для топологии с коротким каналом данная задержка составляет всего один тактовый период (2.5/1.87 ns для 400/533 MHz задающего сигнала), а для конфигурации с полноразмерным — максимум пять циклов синхросигнала (12.5/9.35 ns при частоте синхронизации 400/533 MHz соответственно), в зависимости от удаленности активной микросхемы. В обычных системах с применением синхронного ДОЗУ при выполнении определенной операции одно устройство снимает с себя функции управления, а другое берет, что является причиной минимум однотактного эффекта цикла обращения шины (Turn-around). Поэтому в системе с использованием 100/133 MHz микросхем SDRAM, задержка в один такт между операциями чтения/записи составляет 10/7.5 ns цикл, в то время как в системе на основе 400/533 MHz приборов DRDRAM длительность периода синхросигнала составляет всего 2.5/1.87 ns.
Как и в любой другой сложной системе, в Rambus для точного и четкого функционирования введен цикл инициализации (Initialization), выполняемый по включению питания или после подачи сигнала сброса. Контроллер RMC подготавливает подсистему памяти RDRAM для нормального выполнения операций, используя последовательность транзакций регистров управления. Инициализация настраивает и согласует работу компонент подсистемы, и состоит из четырех основных ступеней: инициализация контроллером и его ядром блока состояния машины (основная составляющая ядра управляющего устройства), инициализация микросхем памяти при помощи четырехпроводного CMOS-интерфейса SCK/CMD/SIO[1:0], установка контроллером определенных в процессе конфигурации необходимых параметров, и установка значений управляющего тока и его скорости нарастания/спада. Тем не менее, в действительности процесс инициализации куда более сложный и разбивается на семь ступеней (о наиболее важных подробнее):
Start Clock. На первой ступени происходит подача синхросигнала и определяются необходимые значения частот для функционирования логических цепей контроллера (PClk — сигнал синхронизации управляющего устройства с логикой внешней системы), блока библиотечного ядра (SClk — сигнал синхронизации внутриблочных операций), формирователя синхросигналов (RefClk — опорная частота), микросхем памяти (CTM/CFM — сигналы синхронизации пакетов команд и данных в канале) и блока последовательной инициализации, а также вычисляются значения коэффициентов умножения (X), деления (A, B, M и N), соотношения (f@PD, Y) и константы передаточной логики (M2m1, N2m1).
RAC Initialization. Вторая ступень заключается в активизации блока инициализации (INIT) макроядра контроллера памяти (RAC — основа канала Direct Channel) и генерировании последовательности импульсов, в процессе которых сбрасывается состояние регистров RAC, выполняется процесс активизации внутренней логики и настраиваются необходимые тайминги для обеспечения стабильности синхронизации и функционирования. Блок INIT состоит из машины состояния и управляющей логики, и выполняет настройку значений PClk/SClk, согласовывая с CTM, и стабилизируя их по частоте и по фазе. Это необходимо для обеспечения согласования между RAC и блоком приложений (Application Unit). Также на этой ступени производится инициализация блока тококонтроля (Current Control) RAC, отвечающего за постоянное слежение и удержание оптимальных значений тока утечки на выходе (IOL) и скорости его нарастания/спада (Slew Rate) для отслеживания температурных девиаций. Данная аппаратная логика занимается фазовой компенсацией сигналов командно-адресного интерфейса и шины данных, а также калибровкой выходных RSL-уровней в зависимости от температуры, напряжения и других сторонних процессов — например, 3s-вариации. Аналогичного рода механизм применяется в SLDRAM — разница заключается исключительно в подходе и конечной аппаратной реализации.
RDRAM Initialization. Третья ступень подразделяется на множество фаз, ориентированных на настройку и оптимизацию работы самих микросхем памяти DRDRAM, выполняемых через блок последовательного интерфейса (SIO). Последовательность конфигурирования микросхем после перерыва на четвертой ступени инициализации контроллера памяти возобновится на пятой, и продолжится на шестой и седьмой. В фазе SIO Reset происходит сброс содержимого шести основных регистров управления микросхемой до начала выполнения транзакции чтения/записи по последовательному интерфейсу: TEST34 (16bit тестовый регистр), CCA (регистр тококонтроля, использующийся для управления выходным током сигнальных линий DQA), CCB (регистр тококонтроля, использующийся для управления током на выходе сигнальных линий DQB), SKIP (регистр для управления переходами между режимами), TEST78 (регистр для тестовый целей) и TEST79 (отладочный регистр). При этом регистр инициализации микросхемы (INIT), содержащий информацию о последовательном номере устройства в системе (SDEVID), управлении переводом в специальные режимы энергосбережения и регенерации (PSX, LSR, NSR и PSR), использовании репитера последовательного интерфейса для проведения инициализации (SRP), управлении температурными сенсорами (TEN, TSQ) и глобальном управлении микросхемой (DIS), переводится в специальное состояние: все биты очищаются (записывается значение «0»), за исключением полей SRP и SDEVID, которые переводятся в «1». В процессе выполнения SIO Reset формирователь синхросигнала последовательного интерфейса (SCK) должен пребывать в выключенном состоянии. В цикле фазы Write TEST77 Register специальный тестовый регистр микросхемы TEST77 должен быть полностью переведен в нулевое состояние (все поля содержат значение «0») до момента, пока в/из любого другого регистра не будет записана/считана информация. Выполняя фазу Write TCYCLE Register, в регистр микросхемы TCYCLE записывается значение длительности периода синхросигнала CTM, определенное на первой ступени инициализации, в размерности 64ps. Цикл Write SDEVID Register играет особенную роль, поскольку в 5bit регистр SDEVID (последовательный номер устройства или персональный последовательный идентификатор) записывается уникальный адрес, и начиная с этого момента разрешено выполнение прямых SIO транзакций чтения/записи. При этом значение адреса микросхемы в канале инкрементируется последовательно от 0 до 31, начиная от ближайшего к контроллеру прибора и до последнего устройства (номер первой микросхемы — 0000, второй — 00001, третьей — 00010,...). После этого возможно выполнение фазы Write DEVID Register, где происходит запись действительного персонального идентификатора устройства (Device ID) в 5bit регистр микросхемы DEVID, после чего становится возможным выполнение полноценных транзакций чтения/записи. Значение, записываемое в данный регистр, совершенно необязательно должно быть идентично значению, хранящемуся в персональном последовательном регистре SDEVID конкретного устройства, поскольку микросхемы памяти в дальнейшем могут быть сортированы в регионы по признакам архитектуры построения массива ядра (количество логических банков, строк, столбцов, адресации и т.д.) — этот механизм помогает в конфигурациях с микшированием устройств различной организации и типа в пределах одного канала. Тем не менее, в случае использования полностью идентичных микросхем в пределах канала, значение последовательного идентификатора просто копируется в регистр DEVID соответствующего устройства. Записываемые данные в регистры PDNX и PDNXA, выполняемые в цикле Write PDNX, PDNXA Register, используются для последующего измерения продолжительности временного интервала выхода из состояние деактивации (PDN). В цикле Write NAPX Register записи данных в регистр NAPX используются значения, применяемые для последующего измерения временного интервала выхода из состояние «дремоты» (NAP). Далее следует фаза Write TPARM Register программирования в регистр TPARM значения задержки между фиксированием микросхемой пакета адреса столбца с командой чтения из памяти (RD) и началом передачи Q-пакета (чтение), содержащего считываемые данные. Этот временной интервал, именуемый tCAC, устанавливается для каждой микросхемы памяти в минимальное разрешенное значение для системы. Более детальная настройка tCAC продолжится на шестой стадии, когда будут известны другие необходимые для этого параметры и закончится ступень конфигурирования контроллера RMC. В регистр TCDLY1, в цикле выполнения фазы Write TPARM Register, дублируется значение регистра TPARM, которое в последующей шестой ступени будет дополнительно настроено. Следующая фаза Write TFRM Register выполняет запись в регистр TFRM значения tRCD временного интервала между приемом пакета адреса строки (ROW) с командой активизации и пакета адреса столбца (COL) с соответствующей командой чтения/записи. Фаза тестирования SETR/CLRR сначала производит запись необходимых значений в соответствующие регистры (TEST78 <— 00416 и TEST34 <— 004016), после чего на каждую микросхему памяти подает команды сброса (SETR — Set Reset Command) и очистки (CLRR — Clear Reset Command) через последовательный интерфейс, выполняя вторичный сброс состояния микросхем, после чего значения тестовых регистров зануляются. Далее производится фаза Write CCA and CCB Register, в процессе которой в регистры CCA и CCB записываются средние между минимальным и максимальным для каждого значения — это необходимо для дальнейшей точной установки управляющего тока, определяемого на пятой ступени. На данный момент микросхемы находятся в деактивированном состоянии (PDN), поэтому в следующей фазе ретрансляция команды выполняется через последовательный блок, чтобы перевести устройства в «расслабленное» состояние (RLX, все логические банки перезаряжены, но ни один не активен), в котором они готовы осуществлять мониторинг ROW-пакетов (адрес строки логического банка и тип операции над ней) собственной адресации. Заканчивается третья ступень фазой подачи команды «быстрой» синхронизации SETF (Set Fast Clock), которая установкой необходимого значения поля AS (автоперевода) регистра SKIP фиксирует микросхемы в специфическом режим фонового безответного чтения на время выполнения четвертой ступени.
Controller Configuration. Четвертая ступень полностью производит инициализацию блока контроллера. Каждая фаза этой стадии устанавливает часть интерфейса шины ConfigRMC[63:0] в соответствующее состояние. Другие части контроллера инициализируются подобным образом, поэтому данную ступень можно рассматривать как руководство. Так, фаза Initial Read Data Offset предназначается для определения первоначальной компенсации временных параметров при чтении данных, записывая по шине значение, определяющее временной интервал между передачей COL-пакета (адрес столбца логического банка и тип операции над ним) с командой чтения и Q-пакета со считываемыми данными. Записываемое значение является минимально разрешенным из всего допустимого диапазона и будет более точно откорректировано на шестой стадии. Вторая фаза Configure Row/Column Timing заключается в определении значений для временных параметров tRAS,MIN (минимальное время произвольного доступа к строке), tRP,MIN (минимальная длительность накопления заряда в строке), tRC,MIN (минимальная длительность полного страничного цикла банка), tRCD,MIN (минимальная задержка адресации «строка-столбец»), tRR,MIN (минимальная задержка адресации «строка-строка») и tPP,MIN (минимальный промежуток времени между «соседними» фазами перезарядки разных логических банков), которые записываются на шину ConfigRMC и номинально совместимы с аналогичными таймингами всех устройств RDRAM в канале. Следующая фаза Set Refresh Interval используется для установки периодичности проведения циклов регенерации каждой строки логического банка микросхемы и заключается в определении и записи на шину максимального значения данного временного параметра (tREF,MAX), единого для всех устройств в канале. Далее, в фазе Set Current Control Interval, производится определение и запись на шину максимально допустимого значения интервала между циклами определения значения управляющего тока (tCCTRL,MAX), единого для всех микросхем памяти в канале. Следующая, аналогичная по свойствам, фаза Set Slew Rate Control Interval записывает на шину единое для всех устройств в канале максимальное значение периодичности проведения цикла термокалибровки (tTEMP,MAX). В цикле последней фазы Set Bank/Row/Col Address Bits четвертой ступени инициализации происходит определение логической организации микросхем памяти в канале: тип ядра (независимая или зависимая расщепленная/сдвоенная структура), количество банков и их организация (количество строк, столбцов).
RDRAM Current Control. Пятая ступень предназначается для проведения фазы настройки управляющего тока микросхемы, где блок INIT генерирует последовательность импульсов, в течение которых устройство производит необходимые для данной стадии операции. Результатом этих настроек являются перепрограммированные значения регистров CCA и CCB каждой микросхемы памяти. Как дополнение, необходимо отметить, что температурный контроль осуществляется «плавающим» состоянием микросхемы между определенными режимами управления питанием (PM — Power Management), которые отличаются количеством одновременно активизированных логических блоков. Согласно спецификации, типичная минимальная температура микросхемы памяти в активном состоянии (ATTN) составляет 50°C, а максимальная — до 100°C включительно. В процессе функционирования подсистемы соответствующий определенному каналу блок RAC производит постоянный мониторинг состояния микросхем (снимает показания термосенсоров), и согласно четко запрограммированным значениям при достижении некоторой температуры вводит устройство в один из режимов РМ. В аварийном случае производится моментальный перевод в режим деактивации — PDN (Power DowN).
RDRAM Core, Read Domain Initialization. Шестая ступень, состоящая из двух фаз, заканчивает инициализацию микросхем памяти. В цикле первой фазы RDRAM Core Initialization посылается 192 транзакции регенерации массива памяти для того, чтобы ввести ядро каждой микросхемы в надлежащее состояние функционирования. В заключительной фазе RDRAM Read Domain Initialization выполняются холостые транзакции чтения/записи для каждой микросхемы, определяя доступную область чтения. Возможность программирования индивидуальной задержки для каждой микросхемы памяти появляется лишь после того, как четко установлена общая задержка чтения, состоящая из задержки распространения сигнала по линии (Propagation Delay), плюс задержка программирования (Programmed Delay). Лишь после выполнения этого условия, в завершение шестой ступени, ранее конфигурируемые регистры TPARM и TCDLY1, содержащие основные временные параметры задержки ядра, у каждой микросхемы перезаписываются с соответствующей поправкой определенной точной задержки чтения, в результате чего интерфейс ConfigRMC контроллера также перезаписывается согласно обновленным данным.
Other RDRAM Register Fields. Седьмая, заключительная ступень инициализации производит считывание и/или запись значений других регистров микросхемы памяти. Так, данные регистра INIT перезаписываются с окончательными определенными значениями полей LSR, NSR и PSR, которые ранее были введены в специальное состояние. В сущности, контроллер должен считать данные всех регистров управления со свойством только для чтения (Read Only) всех микросхем памяти (или считать всю необходимую информацию из микросхемы SPD в составе модуля памяти), проанализировать их, после чего записать необходимые значения во все управляющие регистры для записи (Write Only), чтобы сконфигурировать микросхему для нормального функционирования.
Вообще, третья и последующие ступени инициализации не являются необходимыми, если контроллер памяти может просто по последовательному интерфейсу соединиться с микросхемой SPD, считать из нее данные и запрограммировать необходимые регистры управления микросхемы памяти. Если же в составе модуля нет микросхемы EEPROM с заранее запрограммированными параметрами, то выполняется полный цикл инициализации: используя SIO-транспорт, блок приложений, находящийся в составе контроллера, соединяется через последовательный порт с соответствующим интерфейсом регистров управления микросхемы памяти.
Логический слой DIRECT RAMBUS
Логический слой (Logical Layer) подсистемы определяется механизмом
адресации, управления и пересылки данных, а также типом выполняемых
операций интерфейсов подсистемы. Так, в пределах канала данные и
управляющая командно-адресная информация пересылаются пакетами.
Длительность каждого пакета составляет четыре тактовых цикла или 10ns на
частоте 800MHz, что обуславливает передачу восьми слов, BL=8. Протокол
Direct Rambus стал более упрощенный по сравнению с предыдущим, который
использовался в Base/Concurrent RDRAM-системах, — пакеты управляющей
информации более не мультиплексируются по шине данных. Теперь полностью
физически независимые шины адреса и управления разделены на две группы
сигнальных линий: одна для команд, предназначенных для строки, другая —
для столбца. Данные же передаются по отдельной двухбайтной шине.
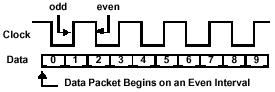
Для реализации полной синхронизации всех активных устройств в канале все пакеты начинаются по срезу (отрицательный перепад, Falling Clock Edge) приходящего тактового сигнала. Пакеты могут начинаться по любому срезу и разделяться между собой по времени (задерживаться) на любое количество циклов синхросигнала. Каждая шина управляется независимо от остальных, передавая команды, адрес или данные одновременно в различные банки микросхемы или вообще в разные микросхемы.
Пакеты адреса строки (ROW Packets), или пакеты доступа к строке, или пакеты строчного доступа (ROW-пакеты) пересылаются по трехпроводному физическому интерфейсу ROW шины адреса/управления. ROW-пакеты включают в себя два типа команд: активизация (Activate или ACT, подобно действию среза сигнала RAS# для EDO DRAM) или подзаряд (Precharge или PRER, подобно действию фронта сигнала RAS#). По команде ACT можно осуществлять пересылку данных в любой банк микросхемы памяти, усилитель уровня которого до этого прошел цикл перезаряда. Другие команды, предусмотренные протоколом логического слоя для данного интерфейса, также могут пересылаться по ROW-шине, включая команды регенерации и управления энергопотреблением. Команды подзаряда могут пересылаться совместно с явным адресом (микросхема, банк), поскольку по замыслу гибкого протокола контроллера существует еще две дополнительные формы операции перезаряда, передающиеся по COL-интерфейсу.
Пакеты адреса столбца (Column Packets), или пакеты доступа к столбцу (COL-пакеты) пересылаются по пятипроводному физическому интерфейсу COL шины адреса/управления. COL-пакеты разделяются на два поля: первое определяет первичную операцию, такую как чтение/запись, а второе поле может содержать команду маскирования (Mask) данных для проведения операции записи или команду для проведения расширенной операции (XOP — eXtended OPeration). В случае выполнения операции маскирования один бит для каждого байта («байт» в этом случае может содержать 8/9 bit информации, что определяется уникальностью реализации механизма коррекции ошибки, ECC) передается как 16bit маскирующего кода на 16-байтный пакет данных. Несколько расширенных команд (XOP-команды) могу использоваться вместо маскирующего поля. Самой распространенной XOP является команда перезаряда. Первичная операция, содержащаяся в COL-пакете, может кодироваться как команда автоподзаряда (AP, Auto-Precharge) совместно с командой чтения/записи, разрешая провести фазу полного перезаряда. Не смотря на то, что COL-пакет является «миксом» двух несимметричных командных полей, посылается он обычно расщепленно: сначала передается основная команда, а Mask/XOP восьмью тиками (размер пакета) позднее. Четырехтактная задержка уменьшает количество промежуточных фаз задвижки, необходимых для удержания информации, если она была изначально послана совместно с пакетом доступа к столбцу.
Пакеты данных (Data Packets или DQ-пакеты) содержат по 16/18 байт
каждый, используя длительность пакетной передачи в 4 цикла синхросигнала
(8 тиков, BL=8), поскольку микросхемы памяти используют 128/144 bit
внутреннюю магистраль данных, передавая по восемь (длина пакета) 16/18 bit
(ширина пакета) слов за каждый доступ к столбцу. По двухбайтной шине
данных за цикл синхросигнала передается 4 байта (по два байта за каждый
тик), а за 10ns — 16/18 байт. Длительность пакета данных аналогична длине
ROW- и COL-пакетов. Поскольку между COL-интерфейсом и шиной данных
соблюдается баланс по пропускной способности, пакетов команд или
упорядочения информации не требуются — это помогает упростить внутреннюю
логику микросхемы памяти до интерфейсной логики обычного ДОЗУ. Контроллер
памяти просто формирует множество COL-пакетов с командами чтения/записи
данных в любом порядке к любой микросхеме с любой открытой страницей.
Обычно полностью произвольный доступ считается завершенным с момента
приема устройством очередной команды активизации (ACT), передающейся по
ROW-шине, следом за которой идет команда чтения/записи по COL-интерфейсу.
После того, как данные считаны, выполняется команда перезаряда (одна из
трех форм) для подготовки банка к следующей фазе произвольного чтения.
Некоторые контроллеры проектируются с возможностью оставлять
активизированную страницу открытой, чтобы потом к ней вернуться с
минимальной задержкой подачи команды на чтение. Данные возвращаются
обязательно через строго фиксированный временной интервал, однако есть
возможность выбора количества тактов синхросигнала, начиная от окончания
действия команды чтения. Эта гибкость варьирования задержкой чтения
актуальна для систем с длинным каналом, где могут присутствовать источники
мультисинхросигнала. В этом случае микросхемы памяти, расположенные в
непосредственной близости от контроллера, программируются с большей
задержкой чтения, а дальние — с меньшей, что позволяет компенсировать
разницу в прохождении сигнала по трассе (задержку распространения). Данная
процедура определения задержек и их программирования в соответствующие
микросхемы памяти происходит в период проведения программы инициализации,
с момента, когда все устройства в канале уже «пронумерованы». Благодаря
четко рассчитанной топологии канала, задержка чтения устанавливается
соответственно присвоенному действительному персональному идентификатору,
характеризующему положение конкретной микросхемы в структуре — в конечном
итоге, ее удаленность от управляющего устройства.
Тайминги транзакции чтения и записи очень похожи, поскольку пакеты
управления посылаются практически одинаково. Тем не менее, одна
значительная разница между RDRAM и обычным DRAM заключается в задержке
записываемых данных для выравнивания относительно таймингов передачи
данных транзакции чтения. Данная задержка выбирается такой, чтобы
максимально использовать полосу пропускания шины данных. В обычной SDRAM,
когда команда чтения следует за командой записи, на шине данных возникает
промежуток (Gap) между этими двумя операциями, который по длительности
эквивалентен задержке чтения из устройства. Если, к примеру, 100MHz
микросхема SDRAM имеет задержку чтения 3T (три такта системной шины), то
необходим 30ns интервал между окончанием фазы записи и началом цикла
чтения. RDRAM свободна от данного интервала, поскольку просто посылает
данные позднее, после чего фактически выполняется последовательность
записи. Команда записи по COL-шине указывает микросхеме какие именно
данные будут записаны в устройство позднее, через четко определенный
интервал — обычно эти данные записываются в массив так скоро, как будут
приняты. Используя как опцию для задержки записи этих данных, можно
разрешать команде чтения опережать (так называемый цикл «Go Around»)
запись, уменьшая эффективную задержку чтения, которая обычно довольно
критична. Тем не менее, основная масса записываемых данных обычно
буферизируется и не является чувствительной к задержке. Если алгоритм
контроллера выбрал этот режим, то проверки одного единственного адреса
будет более чем достаточно, чтобы точно определить соответствие команды
чтения не полностью записанным данным. В этом случае чтение может быть
задержано определенно установленный временной интервал, или данные просто
могут быть возвращены в пределах внутренних схем контроллера инициатору
запроса, экономя полосу пропускания канала на выполнении такой тривиальной
транзакции.
Каждая из команд шины управления может быть конвейеризирована, повышая тем самым ее эффективность использования. Команды ACT могут полностью абсорбировать (занимать) ROW-шину, генерируя небольшие 16-байтные произвольные передачи данных. Если рассматривать это с позиции соотношения размера самой передачи, то по мере увеличения размера передаваемого блока Activate, частота генерирования команд ACT должна пропорционально снижаться. Например, для полной загрузки шины данных достаточно постоянно посылать команды управления столбцами. Исключение составляют маленькие промежутки 1-4 такта синхросигнала, требующие выполнения цикла обращения шины между записью и чтением, что позволяет полностью утилизировать интерфейсы. Так, два цикла записи, следующие за двумя циклами чтения к одному и тому же устройству, дают в результате более 86% эффективности использования, а к нескольким микросхемам — до 95%.
Отдельным интересным механизмом представляется функционирование системы в режиме чередующихся обращений (Interleaved Device Mode), способных практически полностью загрузить протокол шины данных на операциях чтения/записи, и в пике максимально приблизиться к 100% эффективности протокола. Рассматриваемый режим позволяет контроллеру аппаратно по уникальным номерам устройств объединять их в группы по восемь микросхем для коллективной обработки команды, что дает возможность создавать от 1 до 4 (ограничивается максимально допустимым количеством устройств) таких групп в пределах одного канала. Целью данных коллективных ответов на одну команду является ограничение размера каждого пакета данных dualoct (минимально адресуемый участок банка, стандартно составляющий 16/18 байт для обычной и ECC-микросхем соответственно), который считывается/записывается из/в одной микросхемы памяти. Эта возможность позволяет контроллеру при наличии необходимой аппаратной логики продолжать функционирование, производя определение и коррекцию сбоев (временных ошибок, Soft Errors), даже в случае полного отказа (постоянные ошибки, Hard Errors) одной из микросхем в канале. За переключение между обычным и чередующимся режимом работы отвечает бит IDM управляющего регистра инициализации, INIT. Если режим чередующихся обращений выключен, то dualoct обрабатывается стандартно одной микросхемой. В случае активизации коллективной обработки каждая микросхема из группы по восемь устройств отрабатывает свою часть данных: любые 16bit из стандартного 128bit размера dualoct для микросхемы с 16bit внешней шиной данных, или любые 16/24bit из 144bit dualoct с учетом генерирования кода коррекции ошибки для x18 устройства.
{kind=link}
Сравнительный анализ микросхем DRDRAM
Все 128/144 Mbit устройства и первое поколение 256/288 Mbit микросхем памяти DRDRAM основаны на 16d или 2x16d архитектуре, которые вообще содержат 16 или 32 логических банка соответственно. Архитектура 4i, содержащая 4 логических банка, применяется во втором поколении 256/288 Mbit микросхем и стандартизирована для всех приборов памяти емкостью 512/576 Mbit.
Для более конкретного сравнения архитектур 2x16d (или 32s) и 4i микросхем памяти DRDRAM второго поколения детально рассмотрим их сходства и различия на примере 256/288 Mbit приборов. Данные устройства являются высокоскоростными КМОП ДОЗУ, ядро которых содержит 16М слов (емкость массива ядра микросхемы в словах) с шириной 16/18 bit каждое (размер одного слова или внешняя шина данных), определяя общую схему организации как 16Mx16 и 16Mx18 для 256/288 Mbit приборов соответственно. Используя протокол RSL и результирующую частоту функционирования 800/1066 MHz, можно добиться скорости передачи 16bit данных за 1.25/0.93 ns, а 16 байт — за 10/7.5 ns соответственно. Справедливости ради необходимо заметить, что, согласно рекомендациям Rambus, поколение микросхем с зависимой архитектурой (32s) заканчивается на 400MHz частоте синхронизации, в то время как устройства с независимой внутренней организацией (4i) начинаются с 1066MHz эффективной частоты обмена данными. Таким образом, пиковая пропускная способность приборов памяти составляет 1.6GBps для 32-банковой микросхемы и 2.1GBps — для 4-банкового устройства. Тем не менее, в действительности ничего не мешает конечному производителю микросхем реализовать «обратные» решения. Внутренняя архитектура устройств позволяет поддерживать чрезвычайно высокую пропускную способность при выполнении множественных (до четырех) одновременных произвольно адресуемых транзакций. Для снижения полной задержки используется расширенный буфер для записи и три механизма выполнения фазы подзаряда для обеспечения гибкости «согласования» с контроллером памяти. Использование расщепленной шины для управления и обмена данными совместно с независимым строчным и столбцовым арбитражем для максимальной легкости планирования, а также механизмы пакетной передачи данных и коллективной обработки позволяют при абсолютно произвольных обращениях достичь в до 98% эффективности.
Как и любые другие микросхемы памяти, рассматриваемые устройства состоят из двух основных блоков: ядра (Core), включающего в себя логические банки (Bank) c усилителями уровня (SenseAmp), и Direct Rambus-совместимой интерфейсной части, являющейся коммуникационным механизмом для связи с контроллером памяти. Забегая вперед необходимо отметить, что различие в рассматриваемых архитектурах микросхем DRDRAM состоят исключительно во внутренней логической части. Стандартно, массив микросхемы содержит банки (Bank), количество и организация которых определяется фундаментальностью самой архитектуры и конечной емкостью устройства. Банки содержат строки (Row), которые, в свою очередь, содержат столбцы (Column) — матрица, образующаяся такой иерархией, и является ядром микросхемы памяти. Строка — это объем считываемых или записываемых данных в один из нескольких банков ядра. Столбцы — подмножества строк, которые считываются или записываются в индивидуальных фазах операций чтения/записи.
Рассмотрим последовательное продвижение данных по микросхеме RDRAM, которое в силу динамической природы ядра и его синхронной основы функционирования практически ничем не отличается от схемы, используемой в синхронных ДОЗУ. Исключение составляет отсутствие «защелок» адресов строки и столбца (сигналы RAS# и CAS#), принятых в разновидностях SDRAM, ввиду особенностей сигнального интерфейса и пакетного протокола RDRAM. Обычно цикл начинается по приходу команды активизации, которая выбирает конкретный логический банк и необходимую строку в его массиве. В течение следующего цикла информация передается на внутреннюю шину данных и направляется на усилители уровня (своего рода «накопитель», играющий роль как усилителя сигнала, так и временного буфера). Когда усиленный уровень сигнала достигает необходимого значения, данные запираются (Latch) внутренним синхросигналом для ожидания прихода адреса столбца и его определения (декодирования) — процесс, именуемый задержкой между определением адреса строки и столбца (tRCD — Row-to-Column Delay). После выполнения этой задержки команда чтения может подаваться совместно с адресом столбца, чтобы выбрать адрес первого слова, которое надо считать с усилителей уровня. После выставления команды чтения следует задержка доступа к столбцу (tCAC — Column Access Delay), в течение которой данные, считанные из усилителей уровня, синхронизируются и передаются на внешние выводы микросхемы (линии DQ). За первым словом следуют остальные в течение каждого последующего тика, отрабатывая полную установленную длительность пакета (Burst Length) — количество непрерывно передаваемых слов за одну фазу передачи данных. Лишь после того, как вся информация передалась, данные можно возвратить обратно из усилителей уровня в строку пустых ячеек массива для восстановления его содержимого — процесс, именуемый циклом восстановления заряда в странице или подзаряд строки (tRP — Row Precharge time), во время проведения которого данные из массива недоступны. Динамический, обладающий свойством ослабевания сигнала и утечки заряда, по своей природе массив ячеек должен регенерировать (периодически обновлять, подзаряжать) их содержимое. Периоды восстановления заряда, в течение которых поток данных от микросхемы прерывается, устанавливаются регенерирующим контроллером в течение программы мониторинга, выполняемой специальным счетчиком регенерации.
Стандартно цикл строки начинается по команде активизации (Activate, ACT), которая по своей сути считается деструктивной операцией: при переносе бита данных из определенной ячейки ядра в усилитель уровня, его оригинальное значение в массиве микросхемы после считывания принимает состояние, противоположное исходному. В результате необходимо производить операцию восстановления (Restore, RST), которая перезаписывает верное значение бита, находящегося в усилителе уровня, обратно в активизированную строку логического банка — процедура обратного переноса. В момент начала выполнения операции восстановления, данные, находящиеся в усилителе уровня, уже могут проходить фазу чтения/записи (RD/WR). Если в усилитель уровня записывается новая информация, то она автоматически перемещается в банк микросхемы, таким образом делая данные в активной строке и усилителе уровня идентичными. По окончанию операции восстановления активизированный до этого логический банк и соответствующий ему усилитель уровня обязательно должны пройти стадию перезаряда (Precharge, PRE), которая фиксирует их в «обновленном» состоянии до момента подачи следующей команды ACT. Каждая конкретная операция выполняется за определенный минимальный временной интервал (Intervals): активизация происходит за длительность tRCD,MIN, операции восстановления и чтения/записи производятся в течение tRAS,MIN-tRCD,MIN, а для завершения перезарядки необходим промежуток tRP,MIN. Таким образом, полная фаза произвольного обращения к строке состоит из «суммы» длительностей активизации, восстановления данных, их чтения/записи и перезаряда, соответственно образовывая схему доступа ACT-RST-R/W-PRE, умещающуюся во временной интервал tRC, продолжительность которого, в свою очередь, описывается основной тайминговой схемой ДОЗУ — tRCD-tCAC-tRP.
Основным временным параметром, характеризующим быстродействие ядра синхронного ДОЗУ является соотношение tRAS/tRC (динамика массива), определяющее отношение интервала, в течение которого строка открыта для переноса данных (tRAS — Row Active time), к периоду, в течение которого выполняется полный цикл открытия и обновления страницы (tRC — Row Cycle time), также называемый циклом банка (Bank Cycle Time). Цикл банка в свою очередь определяет количество тактов с момента подачи начального адреса страницы, к которой необходимо произвести доступ, до полной ре-активации банка. Длительность активности страницы определяет количество тактов, в течение которых данные доступны до момента начала процедуры перезаряда. Поскольку фаза перезарядки имеет определенную задержку tRP, то полный цикл банка является суммой времени активности страницы и интервала следующего после обращения подзаряда строки: tRC=tRAS+tRP, где tRAS=tRCD+tCAC. Таким образом, tRC характеризует общее количество циклов, входящих в основную тайминговую схему tRCD-tCAC-tRP. Справедливости ради необходимо заметить, что обычно тайминговая схема имеет запись вида tCAC-tRCD-tRP, таким образом указывая степень важности параметров. С другой, более важной, стороны параметр tRAS, именуемый также временем доступа к строке, или длительностью произвольного доступа, или циклом ядра (tRAC — Row Access time, Random Access time или Core Access time), определяет время, в течение которого строка активна и над ней производится необходимая операция.
Так, соотношение tRAS/tRC согласно спецификации составляет 20/28 tCYCLE для всех градаций микросхем памяти DRDRAM, где tCYCLE является длительностью периода задающего синхросигнала и составляет 3.33/2.85/2.50/1.87 ns для микросхем памяти с результирующей частотой передачи данных 600/711/800/1066 MHz. Тем не менее, более детальный анализ позволяет достаточно точно рассчитать цикл ядра, приняв за основу, что длительность задержки tRCD меняется в пределах 7-9 tCYCLE, длительность tCAC лежит в промежутке 7-12 tCYCLE, а задержка tRP составляет 8tCYCLE и является постоянной. Поэтому, принимая во внимание известные значения градаций микросхем памяти DRDRAM, длительность цикла доступа к странице в 30/35ns для приборов с частотой синхронизации 533MHz составляет 16/19 tCYCLE, и соответственно 16/18 tCYCLE — для устройств с 40/45 ns циклом ядра, синхронизирующихся на частоте 400MHz.
Как видно, микросхемы памяти второго поколения обладают наименьшими среди всех серийно выпускаемых ДОЗУ задержками в активном состоянии. Исключение составляют интервалы активизации внутренних цепей по выходу их состояния дремоты (NAP) и деактивации (PDN), называемой еще «глубоким сном». Для уменьшения рассеиваемой мощности микросхемы должны постоянно «плавать» между состояниями активности (ATTN/ATTNR/ATTNW) и ожидания (STBY). Введение устройства в STBY происходит по команде RLX (ReLaX, «расслабленный» режим) для обеспечения обычной ретрансляции адресных пакетов, предназначенных для других микросхем, или отслеживания команд собственной адресации. Переходы в NAP/PDN введены с целью управления энергопотреблением и температурными режимами. В случае ввода микросхемы в режим деактивации, возвращение ее в активное состояние является «экстремально» долгим (так называемый «затяжной прыжок»), поскольку внутренние блоки приема/передачи синхросигнала (RCLK/TCLK) должны пройти полную фазу ресинхронизации с внешним задатчиком. Выход устройства из состояния NAP является менее длительным, нежели из PDN, поскольку синхронизация с формирователем тактовых сигналов в данном режиме поддерживается постоянно.
Логическая основа рассматриваемых устройств DRDRAM — это 32/36 MB ядро, поделенное на 32 банка по 512/576 KB для архитектуры 2x16d, и 256/288 Mbit массив, состоящий из 4 банков по 8/9 MB у 4i-микросхемы. В свою очередь, каждый банк 32s-архитектуры организован по 512 строк, каждая из которых содержит 128 dualocts, каждый из которых содержит 128/144 bit (16/18 байт) и является наименьшей «единицей» (частью) данных, которую можно адресовать и провести над ней необходимую операцию. Иными словами, размер dualoct (или «сдвоенный восьмибайтник», размер одного oct составляет 8 байт) равен ширине интерфейса коммуникации между логическим банком и соответствующим ему усилителем уровня (внутренняя DQA/DQB шина данных): 2х 8 байт при стандартном 16bit внешнем интерфейсе микросхемы, или 2х 8 байт, плюс 2 дополнительных байта ЕСС кода (обусловлено уникальностью подхода реализации применяемого в DRDRAM механизма коррекции ошибки) у микросхемы памяти с 18bit шиной данных. В результате организацию ядра микросхемы памяти с внутренней структурой 32s можно описать по схеме 32x{512x128x128} для 256Mbit прибора и 32x{512x128x144} — для 288Mbit устройства. Каждый банк 4i-архитектуры организован по 4096 строк, каждая из которых содержит 128 dualocts (ширина внутренней шины данных у рассматриваемых архитектур одинакова и составляет 128/144 bit для 16/18 bit внешнего интерфейса). Таким образом, организацию ядра микросхемы памяти со структурой 4i можно описать как 4x{4096x128x128} для 256Mbit прибора и 4x{4096x128x144} — для 288Mbit устройства.
{kind=link}
{kind=link}
Усилитель уровня является не только электрической цепью, обеспечивающей необходимый уровень сигнала на выходных буферах микросхемы, но и логическим блоком, содержащим небольшой массив памяти, с размером, достаточным для размещения половины или целой (в зависимости от архитектуры построения ядра — зависимая/независимая) страницы логического банка микросхемы и сохранения ее содержимого в период проведения цикла регенерации данных в строке. Таким образом, объем логической части усилителя зависит от размера строки сопоставляемого ему логического банка и архитектуры организации ядра. Так, 32s микросхема содержит 34 усилителя уровня, каждый из которых, в свою очередь, содержит 1KB массив (по 512 байт для интерфейсов DQA и DQB отдельно) и может вмещать в себя половину строки одного из ассоциируемого с ним логического банка. Каждый усилитель уровня в архитектуре 2x16d примыкает к двум соседним банкам, исключая цепи 0, 15, 16 и 31, что запрещает одновременный доступ в смежные банки, когда один из них активный. Данный механизм определяет зависимую логическую структуру доступа (Dependent Logic Structure), а схему связи одного усилителя с двумя банками — как логическую пару (Logic Pair). Активизация одного из банков ассоциирует два примыкающих к нему усилителя уровня, тем самым блокируя доступ в два соседних логических банка, также использующие эти усилители — такого рода схема доступа получила название блокируемая тройка (Trio-block), исключая, как уже говорилось, банки 0, 15, 16 и 31. Микросхема архитектуры 4i содержит четыре усилителя, каждый из которых в состоянии вместить в себя 2KB массив (по 1024 байта для интерфейсов DQA и DQB), удерживая целиком одну страницу одного логического банка. Таким образом, этот усилитель уровня может хранить данные любой из 4096 строк ассоциируемого с ним банка. В отличие от рассмотренной выше зависимой структуры, данная схема определяет независимую схему доступа (Independent Logic Structure), при которой любой банк имеет собственный усилитель уровня и может быть доступен в любой момент времени.
Интерфейс шины данных микросхемы (DQA[8:0] и DQB[8:0]) представляет собой 16/18 bit транспорт, по которому передаются считываемые (Q) и записываемые (D) из/в массива памяти данные. Внутренняя шина данных является мультиплексированной 64/72 bit шиной для каждого из DQA/DQB сегментов (в результате — 128/144 bit), функционирующая на 1/8 от результирующей частоты обмена данными в канале. Двунаправленная структура шины данных определяет наличие полноценного мультиплексирующего механизма, состоящего из мультиплексоров (Mux) и демультиплексоров (Demux). Таким образом, само ядро микросхемы DRDRAM (внутренняя организация) функционирует на частоте 100/133 MHz, в восемь раз меньшей результирующей внешней частоты обмена информацией.
Управляющим и командно-адресным транспортом RAMBus является шина RQ[7:0], которая разделяется на две группы: 3bit интерфейс RQ[7:5], именуемый также ROW[2:0], используется для управления строчным доступом, а 5bit шина RQ[4:0], именуемая COL[4:0], — для управления доступом к столбцу. Принцип использования шины ROW[2:0] состоит в управлении обменом данными между логическими банками и соответствующими им усилителями уровня — эти выводы демультиплексируют (командно-адресная шина является однонаправленной) во внутренние 24bit ROWA- (активизация необходимой страницы, ROW Activate) или ROWR- (определенная операция над страницей, ROW Operation) пакеты, которые передаются совместно с ассоциируемыми данными на одинаковой частоте — 100/133 MHz. Шина COL[4:0] применяется для продолжения управления потоком данных уже между усилителями уровня и DQA/DQB интерфейсом — эти выводы демультиплексируют во внутренние 23bit COLC- (определенная операция над столбцом, COL Operation) и один из двух 17bit COLM- (маскирование данных, Mask) или 17bit COLX- (расширенная операция, XOP) пакеты, передающиеся совместно с ассоциируемыми данными.
Так, команда активизации ACT микросхемы с логической организацией 32s, передающаяся в составе ROWA-пакета, применяется для загрузки содержимого одной из 512 страниц данных предварительно выбранного зависимого банка в ассоциируемые с ним усилители уровня — по два усилителя уровня с размером 512 байт для шины DQA и DQB. Вообще говоря, команда активизации строки конкретного логического банка микросхемы DRDRAM ассоциирует два примыкающих к нему усилителя уровня, блокируя при этом доступ в соответственно два смежных банка. Причем, во время выполнения цикла обращения к банку (ACT-RST-R/W-PRE), соседние должны пройти стадию перезаряда. Например, если активизируется банк 5, то усилители уровня 4/5 и 5/6 загрузят в себя содержимое строки, к которой происходит обращение (каждый усилитель вместит половину данных всей строки). Таким образом, пока в банке 5 выполняется операция чтения/записи, обращение (активизация необходимой строки) к смежным банкам 4 и 6 невозможно по причине занятости необходимых усилителей. Команда активизации ACT микросхемы 4i применяется для загрузки содержимого одной из 4096 строк выбранного независимого логического банка в ассоциируемые с ним усилители уровня — один 1KB усилитель для интерфейса DQA и один для DQB.
Команда PRER (введение выбранного банка в цикл перезаряда, передающаяся в поле ROP пакета ROWR) является первичным механизмом (PRER Precharge) проведения подзаряда и применяется для последующей за перенесением данных из банка в усилитель уровня фазы высвобождения (перенос данных из устройства временного хранения обратно в страницу) ассоциируемых усилителей, разрешая активизировать любую строку в этом банке (для 4i и 2x16d логической структуры ядра) или примыкающем, смежном (только для 32s архитектуры).
Команда чтения (RD) является командой передачи данных одного из 128 dualocts (16/18 байт) из конкретного усилителя уровня через мультиплексоры на внешние выводы DQA/DQB канала. Команда записи (WR) в плане маршрутизации является практически обратной команде чтения: данные размером один dualoct загружаются через выводы DQA/DQB в буфер записи (Write Buffer), где также размещается информация о адресе банка (BC, поле адреса банка из COLC-пакета) и столбца (C, поле адреса столбца из пакета COLC). Буфер записи необходим для уменьшения задержки восстановления (цикл между окончанием выполнения предыдущей команды и началом следующей, Turn-Around) внутренней DQA/DQB шины. Данные из буфера записи автоматически возвращаются (записываются с определенной маской) в один из 128 dualocts определенного (согласно данным поля BC) усилителя уровня в течение действия «подпоследовательной» команды COP (поле операционного кода столбца из состава COLC-пакета). Откат может происходить совместно с действием команд RD, WR или NOCOP (команда отсутствия выполнения какой-либо операции, передающаяся в составе поля команды COP) в другое логическое устройство, или во время действия WR или NOCOP в это же устройство (возврат в этом случае во время выполнения команды чтения невозможен). Команды PREC (команда выполнения перезаряда, передающаяся в составе поля команды COP), RDA (команда чтения/подзаряда из состава поля команды COP) и WRA (команда записи/подзаряда из состава поля команды COP) подобны NOCOP, RD и WR соответственно, за исключением того, что фаза подзаряда выполняется в конце операции над столбцом — данные команды определяют второй механизм (PREC Precharge) для проведения цикла подзаряда. После команды чтения или после команды записи с нулевой маской (без маскирования байта, M=0) пакет COLC может использоваться в качестве выполнения расширенной операции (XOP), наиглавнейшей из которых является команда PREX, идущая в составе поля XOP, и определяющая третий, последний механизм выполнения цикла перезаряда — PREX Precharge.
Таким образом, поскольку в основе обмена данными лежит полностью пакетный протокол, обусловленный уникальной узкой расщепленной внешней шиной (отдельной для команд/адреса и данных) и широким внутренним транспортом, в результате для проведения операции над минимально адресуемым объемом данных в 128/144 bit (dualoct или 16/18 байт) необходимо передать 64bit командно-адресной информации: 24bit адреса строки (уникальный номер микросхемы в канале, номер логического банка в составе микросхемы, адрес строки и тип операции над страницей) и 40bit адреса столбца (адрес столбца, разновидность и тип операции над данными).
Архитектура ядра микросхемы DRDRAM: 4I vs 2X16D
В современных микросхемах ДОЗУ матрица ячеек (основа ячейки — транзистор и конденсатор), составляющая ядро микросхемы, делится на несколько суб-матриц, называемых логическими (внутренними или архитектурными) банками (Bank). Такая иерархия преследуют две цели: позволяет производить операции фрагментации над резервируемыми (Redundant) с целью устранения возможных дефектов, возникающих при производстве (RMD — Repaired of Manufacturing Defects), составляющими ядра массива — строки (Word Lines), столбцы (Bit Lines или Data Lines) или отдельные ячейки (Individual Cells), — а также повышать производительность устройства одновременным выполнением совместных операций (Concurrent Operation) и разделением циклов регенерации (конвейеризация), делая их «прозрачными» относительно системы. Банки ядра соединяются внутренней шиной кристалла со специальными электрическими схемами-накопителями, именуемыми усилителями уровня (Sense Amplifier или SenseAmp), которые сохраняют данные одной строки логического банка на период проведения регенерации ее содержимого. Так, усилители уровня занимают намного большую площадь, чем сами ячейки памяти, и располагаются в непосредственной близости от столбцов ассоциируемых с усилителем логических банков, соединяясь с ними внутренней шиной данных.
{kind=link}
Самая длинная часть операции с памятью заключается в доступе к массиву
ядра и считыванию данных по определенному адресу в усилитель уровня (проще
говоря, перенос). Современные компьютерные системы могут генерировать
обращения к памяти быстрее, чем эти операции могут выполняться. Например,
так называемый «конфликт банка» неизбежен, если активны несколько операций
и по меньшей мере два запроса относятся к одному и тому же логическому
банку. Поэтому доступ возможен только по единственному адресу во всем
банке уже после того, как на усилитель уровня передались данные из
активной строки, к которой происходит доступ. С одной стороны, добавлением
большего количества логических банков повышается степень параллелизма,
эффективность отработки операций доступа и выполнения циклов регенерации —
все это достаточно сильно расширяет возможности и гибкость подсистемы
памяти. С другой стороны, каждый дополнительный банк значительно
увеличивает площадь кристалла (и его цену, конечно), включая в себя
дополнительные усилители уровня и логические элементы управления.
Усугубляет положение дел 2N-схема масштабирования логической
структуры ядра, которая однозначно определяет возможное количество банков
в составе микросхемы памяти: 2/4/8/16 и т.д. Таким образом, для баланса
цены и производительности в микросхемах второго поколения DRDRAM была
применена зависимая архитектура построения с использованием сдвоенной
схемы (2х16) организации, которая предполагает расположение усилителей
уровня среди примыкающих банков, образуя логические пары. В данной схеме
конфликты банка имеют место в том случае, когда происходит одновременный
доступ к обоим банкам в логической паре. Например, в паре Bank0-Bank1
доступ ко второму банку блокирует первый, в результате чего схема
зависимой организации банков разрешает доступ только в один банк из пары.

В случае зависимой схемы организации около половины необходимых усилителей уровня, если рассматривать относительно независимой, исключаются, тем самым экономя место на кристалле, уменьшая потребляемую мощность и используя большое количество банков. Единственный эффект сдвоенной архитектуры (DBD — Double Bank Design) состоит в чередующейся активизации смежных банков, что вынуждает один из банков логической пары пройти полную стадию обращения с выполнением цикла перезаряда, чтобы примыкающий открылся для доступа. Для реализации глубокой гибкости функционирования такой схемы используется три механизма перезарядки (об этом подробно говорилось ранее), позволяющие четко определять моменты активности конкретной страницы и создавать планирование очередей доступа — так называемый механизм точного планирования запросов (Exact Sheduling), подобный которому используется, например, в SLDRAM. Так, в фазе перезаряда произвольного банка есть возможность выполнить обновление двух соседних банков из «смежных» логических пар, если они активизированы. Машина состояния (State Machine) в составе контроллера памяти, следящая за текущим состоянием массива микросхем памяти в канале, не должна проверять активность соседних банков, поскольку только необходимый в данный момент банк должен пройти стадию перезаряда, чтобы затем отработать фазу доступа.
Не принимая во внимание индивидуальную структуру ядра, более важной
задачей является уменьшение пенальти, ведущих к конфликту банков, что
решается либо увеличением количества банков в микросхеме, либо общим
количеством банков во всей системе. В системах на базе SDRAM каждая
микросхема отрабатывает только лишь часть запрошенных данных контроллером,
поскольку логические банки (два или четыре — в зависимости от архитектуры
построения и конечной емкости микросхемы) соединяются лишь с частью общей
шины данных подсистемы. Кроме чего, в SDRAM-базируемых системах адресная
шина всегда загружается быстрее, чем шина данных, увеличивая вероятность
возникновения конфликта. Поэтому, если используется однострочный модуль
(один физический банк — суммарная ширина шины данных всех микросхем памяти
в модуле равна ширине шины данных контроллера памяти), вся система в итоге
будет иметь лишь четыре доступных банка. В случае, если система использует
два однострочных модуля или один двухбанковый, общее количество логических
банков увеличивается в два раза по сравнению с однострочной конфигурацией,
и т.д. Управляющее устройство часто конвейеризирует запросы для повышения
производительности, разрешая начать целую последовательность запросов в то
время как предыдущая еще не завершилась. При выполнении полностью
случайных запросов в «однострочной» системе с 4-банковой внутренней
организацией микросхем памяти каждая вторая отложенная (в итоге —
невыполненная) операция создает 25% вероятность возникновения конфликта в
банке (один из четырех банков занят во время запроса), а каждая третья —
50% (два из четырех банков заняты). Таким образом, рассматриваемая
SDRAM-базируемая конфигурация может отложить максимум три операции в любой
момент времени, что ограничивается фундаментальностью базовой архитектуры
— четыре банка в системе. Двухстрочная конфигурация в состоянии сократить
вероятность возникновения конфликтной ситуации в два раза — 12/25 %
соответственно для двух/трех отложенных запросов — по сравнению с
однобанковой.

Технология Direct Rambus DRAM разработана для того, чтобы полный запрос мог целиком обрабатываться отдельной микросхемой памяти, поскольку шина данных каждого устройства полностью перекрывает внешний интерфейс контроллера, поэтому в данном случае понятие физического банка теряет смысл. Кроме чего, поскольку в RAMBus используется расщепленная интерфейсная структура, шины команд/адреса и данных заняты постоянно и загружаются индивидуально, равномерно распределяя нагрузку и балансируя информационные потоки по шинам. Таким образом, используется объединение логических банков по аккумулятивной схеме (или, как ее еще называют, аддитивной), что позволяет банкам всех микросхем в канале суммироваться относительно схемы доступа управляющего устройства (контроллера). Например, при использовании восьми микросхем памяти DRDRAM, базирующихся на 16d архитектуре (шестнадцать зависимых банков), подсистема памяти в результате будет иметь 128 доступных банков. В тоже время, система SDRAM, основанная на восьми микросхемах с 4i архитектурой ядра и х8 внешней организацией одного устройства (8bit шина данных), будет иметь всего четыре банка — сказывается схема наращивания по физическим строкам. Подсистема DRDRAM на основе 4i микросхем памяти не является исключением: каждое устройство в канале добавляет свои внутренние банки в общее число банков в системе. Поэтому данная аддитивная при прочих равных условиях характеристика делает подсистему памяти Direct RDRAM намного более эффективной в плане производительности, нежели эквивалентную по количеству микросхем и их объему SDRAM — с увеличением общего количества банков в системе уменьшается вероятность возникновения конфликтов выполняемых операций, кроме чего экономится время на генерирование нового обращения. Так, исключительно для сравнения, две отложенные транзакции на одну микросхему DRDRAM со структурой ядра 16d или 2x16d (или 32s) при выполнении полностью случайных запросов создают 6.3/3.1 % вероятности возникновения конфликта в банке — один из соответственно 16/32 банков занят. Три невыполненные операции в свою очередь удваивают предыдущие значения до 12.5/6.2 % для 16d/32s архитектуры соответственно. Если же рассмотреть подсистему Direct RDRAM на основе восьми микросхем организации 4i, то шансы на возникновение конфликта точно соответствуют вероятности у микросхемы 32s, поскольку общее количество банков в обоих случаях составляет 32. Как дополнение, можно отметить, что когда запросы происходят быстрее, чем успевают обрабатываться, создавая таким образом «затор», ведущий к их откладыванию, максимальное потенциальное количество невыполненных операций в подсистеме всегда будет на одну меньше, чем общее количество банков в системе. В действительности, не смотря на действующую схему объединения банков, реальное максимально допустимое количество незавершенных транзакций определяет контроллер памяти и его действующий алгоритм — например, у RMC это значение не бывает более восьми.
Производительность микросхем памяти DRDRAM с архитектурами построения банков 2x16d и 4i можно изучить на основе математической модели с конкретными результатами. Для более детального анализа рассмотрим идентичные подсистемы памяти с одной, двумя, четырьмя и восьмью 256Mbit микросхемами с результирующей частотой передачи данных 800MHz и временем активности страницы 45ns. Модель функционирования состоит из 64-байтных передач полностью произвольных шаблонов, «микшируя» 70% операций чтения и 30% записи.
Так, действительная (эффективная) пропускная способность (Real-World Bandwidth) конечной системы и ее эффективность (Efficiency), характеризующая процентный показатель от пиковой пропускной способности, являются наиглавнейшими в данном случае показателями. Для большей наглядности разумно будет также привести разницу в процентном соотношении — дельта производительности, Performance Delta, %.
Реальная пропускная способность исследуемых конфигураций
| Параметр | Действительная пропускная способность в зависимости от количества микросхем | |||
|---|---|---|---|---|
| 1 микросхема | 2 микросхемы | 4 микросхемы | 8 микросхем | |
| 4i | 1164MBps | 1317MBps | 1413MBps | 1468MBps |
| 2x16d | 1306MBps | 1434MBps | 1478MBps | 1499MBps |
| P-Delta | 10.87% | 8.16% | 4.40% | 2.07% |
Как видно из приводимых данных, микросхема памяти с архитектурой 4i обеспечивает минимальную действительную пропускную способность 1.2GBps в самых «жестких» условиях. Тем не менее, по мере добавления микросхем в подсистему, аддитивная архитектура расширяет общее количество логических банков в системе, приближая производительность 4i к 32s, и уже при четырех микросхемах разница в эффективности исследуемых конфигураций становится незначительной.
Эффективность исследуемых конфигураций
| Параметр | Показатель эффективности в зависимости от количества микросхем | |||
|---|---|---|---|---|
| 1 микросхема | 2 микросхемы | 4 микросхемы | 8 микросхем | |
| 4i | 72.75% | 82.31% | 88.31% | 91.75% |
| 2x16d | 81.63% | 89.63% | 92.38% | 93.69% |
| P-Delta | 10.87% | 8.16% | 4.40% | 2.07% |
Для придания гибкости подсистеме памяти управляющее устройство должно обеспечивать работу как с микросхемами 2x16d архитектуры, так и с 4i-приборами. Контроллер памяти RMC2 рекомендуется к применению как многофункциональный и чрезвычайно гибкий, рассчитанный на поддержку обоих типов микросхем DRDRAM второго поколения. В зависимости от требуемых конкретным приложением характеристик доступа к памяти, контроллер может перестраивать «на лету» необходимые параметры для улучшения оптимизации работы подсистемы. В дополнение к стандартному функциональному набору RMC2 можно отдельно добавлять другие способы оптимизации алгоритма работы, такие как операции переупорядочивания, увеличение количества одновременно выполняемых независимых операций, принимая во внимание разделение адресного пространства и схему упорядочивания адресных бит. Отдельные микросхемы памяти содержат участок ПЗУ с заранее прошитыми данными в дополнение к чему имеются опциональные информационные регистры SPD на модуле памяти или просто хранящаяся на системном уровне основная информация о текущей конфигурации, такая как архитектура используемых микросхем памяти, их емкость и частота синхронизации. Контроллер в процессе инициализации в зависимости от выбранного алгоритма может произвести опрос по указываемым выше уровням для определения индивидуальных особенностей установленных в подсистеме устройств, необходимости перегруппировки их в регионы, а также активизации в соответствии с полученной информацией необходимой логики управления. Возможна даже реализация контроллера, который может функционировать с микросхемами памяти Direct RDRAM различной организации, внутренней архитектуры и градации (смешанная конфигурация) в пределах нескольких отдельных каналов практически без эффекта производительности.
Модули памяти RIMM: настоящее и будущее
Как уже говорилось, единственным способом расширения пропускной способности цифрового канала является увеличение его частоты функционирования и ширины шины. Совместное увеличение этих параметров довольно проблематично и имеет быстрое «насыщение», поскольку влияние электромагнитной интерференции (ЭМИ) и частотных эмиссий в этом случае возрастает не линейно. По достижении частоты синхронизации DRDRAM в 533MHz решено было переключиться на расширение шины данных интерфейса RAMBus, поскольку в основе технологии изначально заложена концепция гибкого масштабирования (параллелизм).
Основные характеристики 16/32/64 bit поколений RIMM
| Параметр | 16bit RIMM | 32bit RIMM | 64bit RIMM |
|---|---|---|---|
| Частота синхронизации RSL-интерфейса | 400/533 MHz | 400/533 MHz | 400/533 MHz |
| Результирующая частота RSL-интерфейса | 800/1066 MHz | 800/1066 MHz | 800/1066 MHz |
| Шина данных канала (базовая/ECC) | 16/18 bit | 32/36 bit | 64/72 bit |
| Пиковая пропускная способность канала | 1600/2133 MBps | 3200/4266 MBps | 6400/8532 MBps |
| Минимальное количество микросхем на модуле | 1 | 2 | 4 |
| Максимальное количество микросхем на модуле | 16 | 16 | 16 |
| Количество используемых каналов | 1 | 2 | 4 |
| Протокол общих запросов шины | Нет | Нет | Да |
| Неполная терминация интерфейса на модуле | Нет | Да | Да |
| Количество сигнальных выводов модуля | 184 | 232 | 326 |
| Согласующее сопротивление сигнальной линии | 28W | 40W | 40W |
| Интерфейс общего питания, VDD | 2.5V | 2.5V | 1.8V |
| Напряжение на «набортных» терминаторах, VTERM | Нет | 1.8V | 1.5-1.8 V |
| Mesochronous протокол записи данных | Нет | Нет | Да |
Микросхемы памяти DRDRAM в широких системах объединяются в группы, монтируясь на печатную плату — модуль памяти RIMM (Rambus In-line Memory Module). Модули памяти Direct Rambus первого поколения рассчитаны на монтаж от 4 до 16 устройств и имеют 16/18 bit ширину шины данных. Тем не менее, минимальное количество микросхем на модуле может составлять одно устройство. Принимая во внимание ограничение по нагрузке, базу логического слоя, а также параметры сигнала исходя из общей протяженности сигнальной линии (около 575mm), последовательная структура RAMBus поддерживает функционирование максимально 32 микросхем в одном канале. Исходя из оптимального соотношения между процессами, возникающими на переходах, и масштабируемостью, реальные системы имеют два разъема для модулей на один канал в отличие от рекомендуемых самой Rambus трех.
В основе 16bit модуля RIMM лежит восьмислойная печатная плата с габаритными размерами 133.35x34.93x1.27 mm (5.25x1.375x0.05 inch), содержащая 184 позолоченные контактные площадки сигнальных выводов, половина из которых приходится на заземление (применяется схема чередования типа «сигнал/экран» для улучшения помехозащищенности). Рекомендуемое количество замен модулей для разъема (Insertion/Withdrawal cycle, цикл полной замены) составляет 25 вставок/изъятий. На одном 16bit модуле RIMM обычно размещается 4, 8 или 16 микросхем памяти, каждая схема из которых имеет свои правила размещения устройств на плате.
{kind=link}
{kind=link}
Ввиду совершенствования технологии, а также с целью улучшения интеграции подсистемы памяти, были разработаны 32bit модули RIMM. Данное решение базируется на объединении двух 16/18 bit каналов (A и B) RAMBus в одну магистраль для компактности и гибкости системного проектирования. Так, канал A является «сквозным» относительно модуля, обеспечивая соединение к/от контроллера, разъема или нагрузочных резисторов. Канал B терминируется на модуле и обеспечивает коммуникацию от контроллера или другого слота памяти. В основе данного модуля лежит печатная плата с габаритными размерами 133.35x34.93x1.27 mm (5.25x1.375x0.05 inch), содержащая 232 позолоченные контактные площадки сигнальных выводов. Так, модули, использующие монтаж микросхем памяти с двух сторон (более 8 микросхем памяти), базируются на восьмислойной печатной плате, а односторонние модули (8 устройств и менее) — на шестислойной основе.
{kind=link}
Поскольку канал является терминируемой линий передачи, он структурно соединяет ASIC с серией оконечных сопротивлений. Отличительной особенностью подсистемы на базе 32bit RIMM является перенос серии терминирующих резисторов (согласующая нагрузка) непосредственно на модуль памяти, что повлекло за собой полный пересчет топологии сигнальных трасс и общей продолжительности каждого канала. Тем не менее, на правила электрического соединения это не оказывает никакого эффекта: как обычно, все разъемы должны быть заполнены или 32bit модулями RIMM, или продолжителями канала («пустышками») с аналогичным интерфейсом, которые также имеют набортную терминацию. Хотелось бы в дополнение отметить, что поскольку в 32bit модулях RIMM два отдельных канала объединены в один, а реальное количество слотов расширения подсистемы составляет как и ранее два разъема, наращивать объем памяти разумно, используя микросхемы с емкостью 512/576 Mbit.
Поскольку в пределах одного контроллера RMC можно организовать максимум четыре канала (каждый управляется отдельным RAC), то последним словом в генерации RIMM стал модуль с 64bit интерфейсом, увеличив общее количество собственных сигнальных выводов до 326. Такая высокая плотность достигается благодаря 0.75mm промежутку между соседними выводами в отличие от 1mm интервала у 16/32 bit модулей. В основе этого решения лежит объединение четырех 16/18 bit каналов (A, B, C и D) RAMBus. Роутинг структуры сигнального интерфейса 64bit модуля представляет собой своего рода практически дублирование схемы, использующейся в 32bit RIMM. Каналы B и D являются «сквозными» относительно модуля, обеспечивая соединение к/от контроллера, разъема или нагрузочных резисторов. В свою очередь, каналы A и C терминируются на модуле, обеспечивая коммуникацию от контроллера или другого слота памяти. Стандартные габаритные размеры 133.35x34.93x1.27 mm (5.25x1.375x0.05 inch) и восьмислойная основа (печатная плата) модуля делают его процесс производства на ранних стадиях совместимым с 16/32 bit модулями и максимально облегченным. Тем не менее, поскольку описываемые генерации RIMM не являются взаимозаменяемыми, конфигурация механических выемок-ключей у них совершенно разная.
{kind=link}
Все генерации RIMM используют общие CMOS-уровни питания и сигнальный интерфейс RSL. Для более наглядного понимания архитектурных особенностей данных модулей еще раз кратко рассмотрим основные моменты сигнального интерфейса RAMBus. Как уже упоминалось, в основе интерфейса устройств памяти DRDRAM лежат две высокоскоростные шины: запросов (командно-адресный интерфейс, RQ) и данных (DQ). Низкоскоростная шина используется для проведения инициализации и управления питанием. Так, шина запроса является 8bit интерфейсом, использующимся для передачи команд и адреса от контроллера памяти к микросхеме, синхронизирующиеся сигналом исходящей дифференциальной синхропары CFM/CFMN. В свою очередь, 16/18 bit двунаправленная шина данных, логически подразделяющаяся на A и B байты, применяется для передачи информации при выполнении основных операций памяти. Записываемые данные передаются от контроллера памяти к микросхеме, синхронизируясь исходящим сигналом, в то время как считываемые данные идут в обратном направлении, синхронно с входящей синхропарой CTM/CTMN.
Рассматриваемая
высокоскоростная RSL-структура состоит из сигнальных линий,
начинающихся от контроллера, проходящих через все микросхемы памяти, и
заканчивающихся на серии терминаторов. Нагрузочные сопротивления, в свою
очередь, служат для согласования полного сопротивления шины, к которой
подключены устройства — иными словами, сопротивление нагрузки должно быть
равно сумме сопротивления источника и сигнальной линии. В результате,
согласование достигается благодаря резистору, смещающему логический
уровень на величину VTERM.
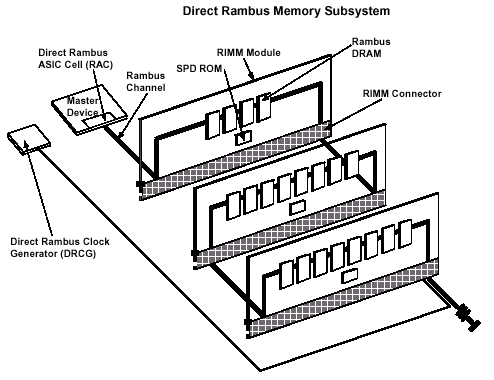
В системе, использующей 16bit RIMM, структура шин запроса и данных идентична и имеет «сквозной» роутинг — весь высокоскоростной интерфейс начинается от контроллера, проходит через все имеющиеся разъемы и модули, и заканчивается на серии нагрузочных сопротивлений. Пара CTM формируется задатчиком синхросигнала DRCG от дальнего конца структуры и распространяется по направлению к контроллеру, где разворачивается и становится парой CFM. Синхросигнал CFM, в свою очередь, распространяется в направлении движения сигналов командно-адресной шины от контроллера и терминируется по выходу из последнего разъема. Таким образом обеспечивается согласование и все сигналы поглощаются нагрузкой в самом конце структуры лишь после того, как проходят все модули.
32bit
RIMM используют согласование на системном уровне (System-level
Termination), определяющее частичную (неполную) терминацию (Partial
Termination) RSL-интерфейса непосредственно на модуле памяти. Так, в
центре модуля располагается серия нагрузочных сопротивлений для
высокоскоростных структур, а для CMOS-интерфейса терминаторы находятся в
правой части (согласно цоколевке) модуля памяти. Иными словами, схема
терминирования, используемая в 32bit модулях RIMM, не привязана к
конкретному месторасположению в самой структуре нагрузочных сопротивлений.
Так, только половина (16/18 bit) общей шины данных (32/36 bit)
«прерывается» на первом модуле, в то время как вторая половина имеет
сквозной роутинг и может терминироваться либо непосредственно на
материнской плате (если используется лишь одномодульная конфигурация),
либо продолжиться на втором модуле памяти и согласоваться уже на нем.
Терминация CMOS-интерфейса осуществляется только на модуле (On-module
Termination).
{kind=link}
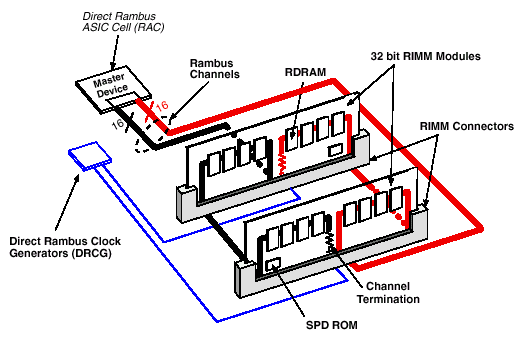
Допуская более упрощенный по сравнению с 16bit подсистемой интерфейс, применяемый в 32bit RIMM уровень напряжения на терминаторах VTERM позволяет понизить рабочий диапазон до 1.5V, что уменьшает потребляемую мощность микросхем памяти. В дополнение, увеличенный номинал согласующего сопротивления в 40W позволяет сужать сигнальные трассы и ведет к понижению рассеиваемой на терминаторах мощности.
Подсистема памяти, поддерживающая 64bit RIMM, обеспечивает все необходимое, что может только потребоваться для реализации такой высокой пропускной способности, гибкости использования и обратной совместимости — это и обеспечение максимально необходимой пропускной способности при помощи только одного модуля, и контроллер, поддерживающий полную вертикаль генераций RIMM c 64, 16 или 32 bit интерфейсом, и менее ограничивающие требования к роутингу сигнальных трасс, и более упрощенные методы монтажа, и четырехслойная основа подсистемы на материнской плате, и улучшенный интерфейс питания с заделом на будущие технологические нормы проектирования, а также уменьшенное напряжения питания микросхем, способствующее снижению потребляемой мощности и увеличению времени жизни полупроводника.
В 16/32 bit модулях RIMM шины данных и адреса разводятся совместно, и должны совпадать по протяженности и оконечной нагрузке. В отличие от этого, 64bit модуль использует всего лишь одну шину подачи запроса с единственной дифференциальной исходящей синхропарой, осуществляющей передачу командно-адресной информации для полного (64/72 bit) интерфейса шины данных RIMM. Эта особенность в значительной степени упрощает топологию модуля памяти и материнской платы, кроме чего уменьшает общее количество используемых сигнальных линий всей структуры в целом. Поэтому «совместная» шина адреса совершенно не обязательно должна совпадать по протяженности со структурой шины данных. Таким образом, общее количество выводов 64bit RIMM, насчитывающее 326 сигнальных линий, значительно меньше, чем если использовать тривиальное объединение четырех каналов: теперь на шину запроса RQ приходится 8 выводов, шина данных DQ имеет 108 сигнальных линий, интерфейс исходящих CFM/CFMN сигналов не изменился (2 линии), а вот входящих CFM/CFMN увеличился до 12 выводов. Кроме этого, интерфейс терминирующего напряжения VTERM и питающий интерфейс VDD используют 16/12 сигнальных линий соответственно, а общее количество экранирующих трасс GND увеличилось до 150, по-прежнему используя схему чередования «сигнал-земля». В дополнение хотелось бы заметить, что, принимая во внимание геометрические и физические параметры данного модуля, потенциал RIMM на данном этапе можно считать исчерпанным, поскольку в 64bit версии неприсоединенные (NC, зарезирвированные) и неиспользуемые (NU) сигнальные линии отсутствуют.
{kind=link}
Поскольку в основе данного модуля, как и в предыдущих двух модификациях RIMM, лежит интерфейс последовательного соединения устройств в канале, использующих n-канальную структуру, основанную на МДП-транзисторе с открытым ненагруженным стоком (Open-Drain NMOS Structure), то по-прежнему требуется согласование сигнальных линий. Как и 32bit модуль памяти, 64bit RIMM поддерживает терминирование на системной уровне. Так, шина команд/адреса полностью терминируется на модуле. Тем не менее, только половина (32/36 bit) всей шины данных (64/72 bit) имеет согласующие резисторы на первом модуле, а другая половина является «сквозной» и продолжается на следующем.
{kind=link}
Так как канал RAMBus является синхронизируемой структурой, все команды и данные согласуются по фронту/срезу соответствующих синхросигналов. На таких частотах функционирования требуется особая осторожность при реализации минимизации перекоса (расхождение по временной оси в очень узком окне) между синхросигналом и сигналами интерфейса адреса/данных. На физическом уровне все считываемые данные передаются синхронно с сигналом CTM, собственным для каждого 16/18 bit канала. Записываемые данные в момент отправки контроллером по каждому каналу должны быть совместно выровнены, синхронизируясь с одним-единственным сигналом CFM. Такая уникальная система согласования дает возможность максимально упростить топологию подсистемы на материнской плате и ее трассировку, поскольку шина данных должна совпадать с по протяженности с CTM, а командно-адресная структура — с CFM. При этом совершенно не обязательно соблюдать идентичность протяженности структур каналов, составляющих интерфейс шины данных, или продолжительность шины данных и шины запросов.
Интерфейсы используемых напряжений в 64bit модуле очень похожи на применяемые в 32bit версии RIMM. Понижение напряжения на терминаторах до 1.5V и увеличение импеданса до 40W позволяет понизить рассеиваемую мощность на нагрузках и потребляемую в расчете на один корпус. Кроме этого, уменьшение питающего напряжения микросхемы со стандартных 2.5V до 1.8V дает возможность 64bit модулям функционировать в температурных условиях, соответствующих 16bit RIMM, причем практически исключая дополнительные средства охлаждения.
Для обслуживания 64bit модулей должен применятся контроллер с соответствующим количеством каналов, управляемых определенным числом RAC в зависимости от реализации. Например, RMC может быть спроектирован таким образом, чтобы осуществлялась поддержка как 64bit модулей, так и RIMM с 16bit интерфейсом — такого рода управляющее устройство обеспечивает максимальную гибкость и, думается, не лишнюю обратную совместимость.
Список рекомендуемых источников
- Rambus Technology Overview, http://www.rambus.com/
- RDRAM Performance Analysis: 2x16 versus 4i Bank Architecture, http://www.rambus.com/
- 1066MHz RDRAM (4Mx16/18x4i) 256/288 Mb, http://www.rambus.com/
- Direct RDRAM 256/288-Mbit (512Kx16/18x32s), http://www.rambus.com/
- Concurrent RDRAM 16/18Mbit (2Mx8/9) & 64/72Mbit (8Mx8/9), http://www.rambus.com/
- Concurrent RDRAM User Guide, http://www.rambus.com/
- Rambus 32 and 64 bit RIMM Module Technology Summary, http://www.rambus.com/
- Rambus RIMM Module (with 256/288Mb RDRAMs), http://www.rambus.com/
- Rambus RIMM 2100 Module (with 256/288Mb RDRAM Devices), http://www.rambus.com/
- Rambus 32 Bit RIMM Module (with 256/288Mb RDRAM Devices), http://www.rambus.com/
- Rambus 64 Bit RIMM Module (with 256/288Mb RDRAM Devices), http://www.rambus.com/
- Direct Rambus Long Channel Design Guide, http://www.rambus.com/
- Direct Rambus Short Channel Layout Guide, http://www.rambus.com/
- A 1.6 Gbit/s/pin Multilevel Parallel Interconnection, http://www.rambus.com/
- RDRAM 32 Bit RIMM Connector, http://www.rambus.com/
- 32 Bit RIMM Continuity Module, http://www.rambus.com/
- Direct RMC.d1 Data Sheet, http://www.rambus.com/
- Direct Rambus Memory Controller (RMC2), http://www.rambus.com/
- Direct RAC Data Sheet, http://www.rambus.com/
- Dual Direct Rambus Clock Generator, http://www.rambus.com/
- Direct Rambus Clock Generator Validation Specification, http://www.rambus.com/